
Zaoqi's Blog -> Python数据分析教程 -> 图解Pandas ->
数据聚合
数据聚合¶
在线刷题
检查 or 强化 Pandas 数据分析操作?👉在线体验「Pandas进阶修炼300题」
Note
本页面代码可以在线编辑、执行!
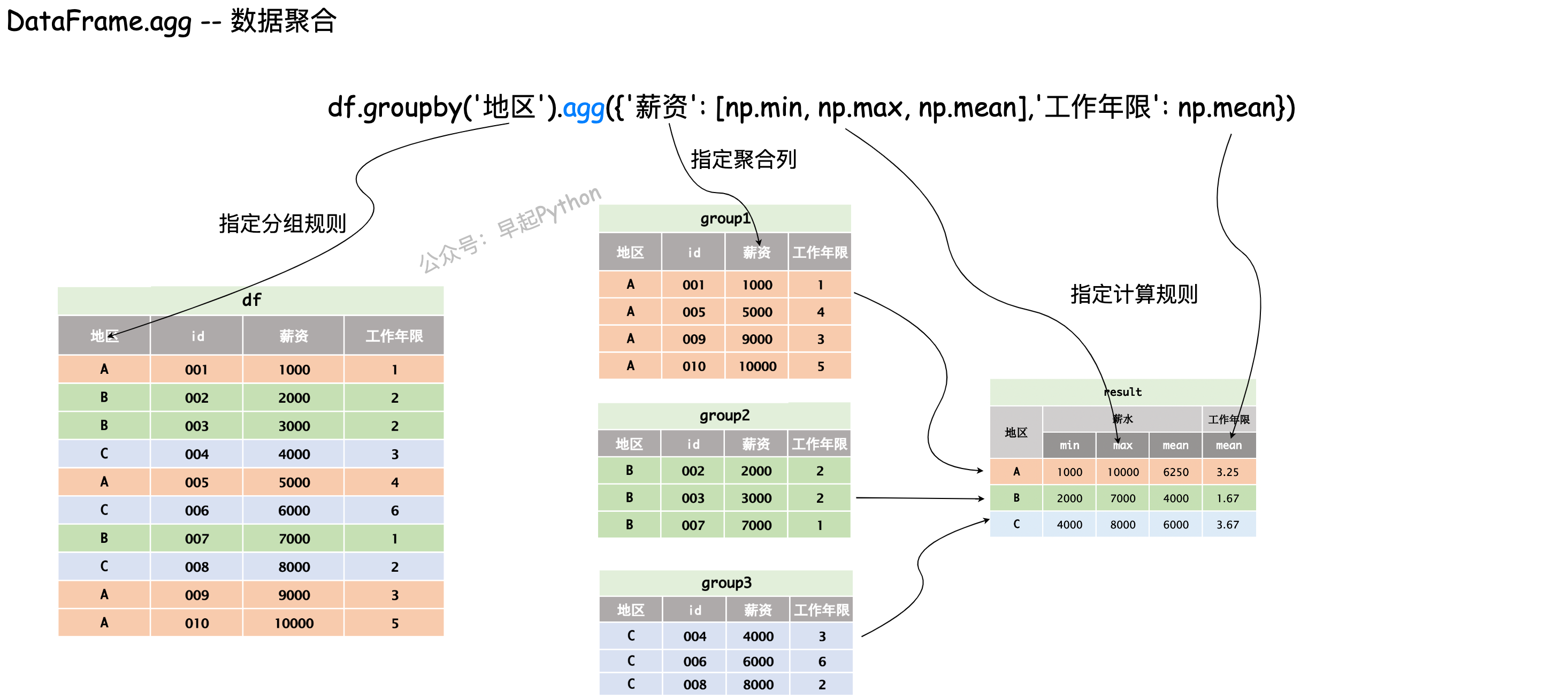
数据聚合可以在数据分组的基础上,进一步对不同列采取不同的计算规则,例如查看不同地区的员工薪资最大、最小、均值以及工作年限的均值,过程图解如下
下面是更多相关案例,你可以修改相关代码来验证自己的想法!
本页数据说明¶
为了更好的介绍相关操作,本页面使用 某招聘网站数据.csv 数据进行展开,你应该对数据字段、数值、类型等相关信息做一个大致了解!
import pandas as pd
pd.set_option('display.max_colwidth',8)
df = pd.read_csv("某招聘网站数据.csv",parse_dates=['createTime'])
df.head()
| positionName | companySize | industryField | financeStage | companyLabelList | firstType | secondType | thirdType | createTime | district | salary | workYear | jobNature | education | positionAdvantage | imState | score | matchScore | famousCompany | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 数据分析 | 50-150人 | 移动互联... | A轮 | ['绩效... | 产品|需... | 数据分析 | 数据分析 | 2020-... | 余杭区 | 37500 | 1-3年 | 全职 | 本科 | 五险一金... | today | 233 | 15.1... | False |
| 1 | 数据建模 | 150-... | 电商 | B轮 | ['年终... | 开发|测... | 数据开发 | 建模 | 2020-... | 滨江区 | 15000 | 3-5年 | 全职 | 本科 | 六险一金... | disa... | 176 | 32.5... | False |
| 2 | 数据分析 | 2000人以上 | 移动互联... | 上市公司 | ['节日... | 产品|需... | 数据分析 | 数据分析 | 2020-... | 江干区 | 3500 | 1-3年 | 全职 | 本科 | 五险一金... | today | 80 | 14.9... | False |
| 3 | 数据分析 | 500-... | 电商 | D轮及以上 | ['生日... | 开发|测... | 数据开发 | 数据分析 | 2020-... | 江干区 | 45000 | 3-5年 | 全职 | 本科 | 年终奖等 | thre... | 68 | 12.8... | True |
| 4 | 数据分析 | 2000人以上 | 物流丨运输 | 上市公司 | ['技能... | 产品|需... | 数据分析 | 数据分析 | 2020-... | 余杭区 | 30000 | 3-5年 | 全职 | 大专 | 五险一金 | disa... | 66 | 12.7... | True |
聚合统计¶
计算指标¶
分组计算不同行政区,薪水的最小值、最大值和平均值
import numpy as np
df.groupby('district')['salary'].agg([min, max, np.mean])
| min | max | mean | |
|---|---|---|---|
| district | |||
| 上城区 | 22500 | 30000 | 2625... |
| 下沙 | 30000 | 30000 | 3000... |
| 余杭区 | 7500 | 60000 | 3358... |
| 拱墅区 | 24000 | 30000 | 2850... |
| 江干区 | 3500 | 45000 | 2525... |
| 滨江区 | 7500 | 50000 | 3142... |
| 萧山区 | 25000 | 45000 | 3625... |
| 西湖区 | 6500 | 45000 | 3089... |
修改列名¶
将上一题的列名(包括索引名)修改为中文
df.groupby('district').agg(最低工资=('salary', 'min'), 最高工资=(
'salary', 'max'), 平均工资=('salary', 'mean')).rename_axis(["行政区"])
| 最低工资 | 最高工资 | 平均工资 | |
|---|---|---|---|
| 行政区 | |||
| 上城区 | 22500 | 30000 | 2625... |
| 下沙 | 30000 | 30000 | 3000... |
| 余杭区 | 7500 | 60000 | 3358... |
| 拱墅区 | 24000 | 30000 | 2850... |
| 江干区 | 3500 | 45000 | 2525... |
| 滨江区 | 7500 | 50000 | 3142... |
| 萧山区 | 25000 | 45000 | 3625... |
| 西湖区 | 6500 | 45000 | 3089... |
组合计算¶
对不同岗位(positionName)进行分组,并统计其薪水(salary)中位数和得分(score)均值
df.groupby('positionName').agg({'salary': np.median, 'score': np.mean})
| salary | score | |
|---|---|---|
| positionName | ||
| BI数据分析师 | 20000 | 2.66... |
| bi数据分析师 | 40000 | 5.00... |
| 业务与数据分析师 | 30000 | 3.00... |
| 产品经理/数据分析(核心业务)-2020届春招 | 60000 | 3.00... |
| 产品运营(偏数据分析) | 27500 | 15.0... |
| 商业数据分析 | 35000 | 0.00... |
| 商业数据分析师 | 37500 | 5.00... |
| 商业数据分析师(阿里数据银行) | 22500 | 3.00... |
| 大数据分析工程师(J11108) | 30000 | 17.0... |
| 大数据建模总监 | 37500 | 14.0... |
| 奔驰·耀出行-BI数据分析专家 | 30000 | 0.00... |
| 奔驰耀出行-战略数据分析师 | 42500 | 1.00... |
| 店铺数据分析师 | 30000 | 6.00... |
| 数据分析 | 30000 | 82.7... |
| 数据分析-2020届春招 | 30000 | 4.00... |
| 数据分析专员 | 26250 | 3.00... |
| 数据分析专家 | 31250 | 8.16... |
| 数据分析专家-LQ(J181203029) | 21500 | 0.00... |
| 数据分析专家03-10-217 | 23750 | 4.50... |
| 数据分析专家(游戏业务) | 37500 | 12.0... |
| 数据分析实习生 | 40000 | 4.00... |
| 数据分析实习生 (MJ000087) | 26500 | 3.00... |
| 数据分析工程师 | 20000 | 16.0... |
| 数据分析师 | 37500 | 6.50... |
| 数据分析师 (MJ000250) | 27500 | 4.50... |
| 数据分析师(J10147) | 37500 | 3.00... |
| 数据分析师-Lark | 30000 | 2.00... |
| 数据分析师-企业SaaS应用 | 40000 | 2.00... |
| 数据分析师/BI | 45000 | 5.00... |
| 数据分析师(保险)13-01-19 | 40000 | 4.00... |
| 数据分析师(社招) | 30000 | 15.0... |
| 数据分析师(财务方向) | 37500 | 5.00... |
| 数据分析建模工程师 | 30000 | 0.00... |
| 数据分析建模工程师(校招) | 36500 | 0.00... |
| 数据分析经理 | 30000 | 6.50... |
| 数据分析负责人 or 数据分析师 | 30000 | 4.00... |
| 数据建模 | 15000 | 176.... |
| 数据建模专家-杭州-01546 | 30000 | 12.0... |
| 数据建模工程师 | 36250 | 24.0... |
| 旅游大数据分析师(杭州) | 30000 | 1.00... |
| 智能数据分析引擎研发专家 | 30000 | 3.00... |
| 浙江数据分析师 | 37500 | 5.00... |
| 解决方案顾问/数据分析师 | 25000 | 4.50... |
| 财务数据分析师 | 37500 | 4.50... |
| 资深数据分析/数据分析专家G00796 | 45000 | 4.00... |
| 资深数据分析专员 | 30000 | 1.00... |
| 资深数据分析师 | 30000 | 6.66... |
| 资深数据分析师 (MJ000088) | 25000 | 4.00... |
| 资深数据分析师(商品方向)G01053 | 45000 | 4.00... |
| 资深数据分析师(杭州) | 37500 | 15.0... |
| 金融数据分析师 | 22500 | 5.00... |
| 银行数据分析岗 | 50000 | 5.00... |
| 高级数据分析专员 | 22500 | 4.00... |
| 高级数据分析师 | 30000 | 3.66... |
| 高级财务数据分析师 | 28750 | 4.50... |
多层统计¶
对不同行政区进行分组,并统计薪水的均值、中位数、方差,以及得分的均值
df.groupby('district').agg(
{'salary': [np.mean, np.median, np.std], 'score': np.mean})
| salary | score | |||
|---|---|---|---|---|
| mean | median | std | mean | |
| district | ||||
| 上城区 | 2625... | 26250 | 5303... | 2.00... |
| 下沙 | 3000... | 30000 | NaN | 6.00... |
| 余杭区 | 3358... | 30000 | 1085... | 15.1... |
| 拱墅区 | 2850... | 30000 | 3000... | 2.75... |
| 江干区 | 2525... | 26250 | 1725... | 39.2... |
| 滨江区 | 3142... | 30000 | 1044... | 12.9... |
| 萧山区 | 3625... | 37500 | 1030... | 18.2... |
| 西湖区 | 3089... | 30000 | 7962... | 8.06... |
自定义函数¶
在 18 题基础上,在聚合计算时新增一列计算最大值与平均值的差值
def myfunc(x):
return x.max()-x.mean()
df.groupby('district').agg(最低工资=('salary', 'min'), 最高工资=(
'salary', 'max'), 平均工资=('salary', 'mean'), 最大值与均值差值=('salary', myfunc)).rename_axis(["行政区"])
| 最低工资 | 最高工资 | 平均工资 | 最大值与均值差值 | |
|---|---|---|---|---|
| 行政区 | ||||
| 上城区 | 22500 | 30000 | 2625... | 3750... |
| 下沙 | 30000 | 30000 | 3000... | 0.00... |
| 余杭区 | 7500 | 60000 | 3358... | 2641... |
| 拱墅区 | 24000 | 30000 | 2850... | 1500... |
| 江干区 | 3500 | 45000 | 2525... | 1975... |
| 滨江区 | 7500 | 50000 | 3142... | 1857... |
| 萧山区 | 25000 | 45000 | 3625... | 8750... |
| 西湖区 | 6500 | 45000 | 3089... | 1410... |
On this page