
Zaoqi's Blog -> Python数据分析教程 -> 图解Pandas ->
Pandas 对比 Excel
Pandas 对比 Excel¶
为了方便长期使用 Excel 的用户转到 Pandas,我将结合官方文档对部分操作进行对比
在线刷题
检查 or 强化 Pandas 数据分析操作?👉在线体验「Pandas进阶修炼300题」
数据结构¶
通用术语对比¶
pandas |
Excel |
|---|---|
|
工作表 |
|
列 |
|
索引 |
row |
行 |
|
空值 |
DataFrame¶
pandas 中的 dataframe 类似于Excel 工作表。虽然一个 Excel 工作簿可以包含多个工作表,但通常情况下 pandas.DataFrame是独立存在的。
Series¶
Series是表示 DataFrame一列的数据结构。使用 Series 类似于引用电子表格中的一列。
Index¶
每个 DataFrame 和 Series 都有一个 Index,它是数据行的标签。在pandas中,如果没有指定索引,则默认使用RangeIndex(第一行= 0,第二行= 1,等等),类似于电子表格中的行标题/数字。
在 pandas 中,索引可以设置为一个(或多个)惟一值,这就像在工作表中有一列用作行标识符一样。与大多数电子表格不同,这些Index值实际上可以用来引用行。(注意,这可以在Excel的结构化引用中完成。)例如,在电子表格中,您可以引用第一行为 A1:Z1,而在 pandas 中,您可以使用population .loc['Chicago']。
常见操作对比¶
为了更方便介绍 Pandas 相关功能,方便长期使用 Excel 进行数据分析的用户学习,下面是常见操作的 Excel 与 Pandas 实现对比。
1 - 数据读取¶

Pandas¶
Pandas支持读取本地Excel、txt文件,也支持从网页直接读取表格数据,只用一行代码即可,例如读取上述本地Excel数据可以使用pd.read_excel("示例数据.xlsx")
import pandas as pd
pd.read_excel("示例数据.xlsx") #将示例数据.xlsx放在该Notebook同一文件夹下
| 创建时间 | 地址 | 岗位 | 学历 | 技能要求 | 工作经验 | 薪资水平 | |
|---|---|---|---|---|---|---|---|
| 0 | 2020-03-16 12:28:11 | 广州 | 数据开发 | 本科 | ['Hive', '数据挖掘', '数据分析'] | 3-5年 | 20000.0 |
| 1 | 2020-03-16 12:39:03 | 广州 | 数据分析 | 本科 | ['数据分析', '数据库'] | 1-3年 | 13000.0 |
| 2 | 2020-03-16 12:01:37 | 广州 | 数据分析 | 本科 | ['数据分析', '商业'] | 应届毕业生 | 8000.0 |
| 3 | 2020-03-16 11:19:51 | 广州 | 数据分析 | 本科 | ['SQL', '数据分析', '数据库'] | 3-5年 | 20000.0 |
| 4 | 2020-03-16 11:18:49 | 广州 | 数据分析 | 大专 | ['数据分析'] | 1-3年 | 8000.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 820 | 2020-03-16 11:20:44 | 深圳 | 数据分析 | 本科 | [] | 1年以下 | 11500.0 |
| 821 | 2020-03-16 11:20:42 | 深圳 | 数据开发 | 本科 | [] | 应届毕业生 | 4500.0 |
| 822 | 2020-03-16 10:33:46 | 深圳 | 数据分析 | 本科 | ['BI', '数据分析', 'SQL', '数据库'] | 3-5年 | 16500.0 |
| 823 | 2020-03-16 11:20:43 | 深圳 | 数据开发 | 本科 | [] | 不限 | 11500.0 |
| 824 | 2020-03-16 10:37:24 | 深圳 | 数据分析 | 本科 | [] | 不限 | 3000.0 |
825 rows × 7 columns
2 - 数据生成¶
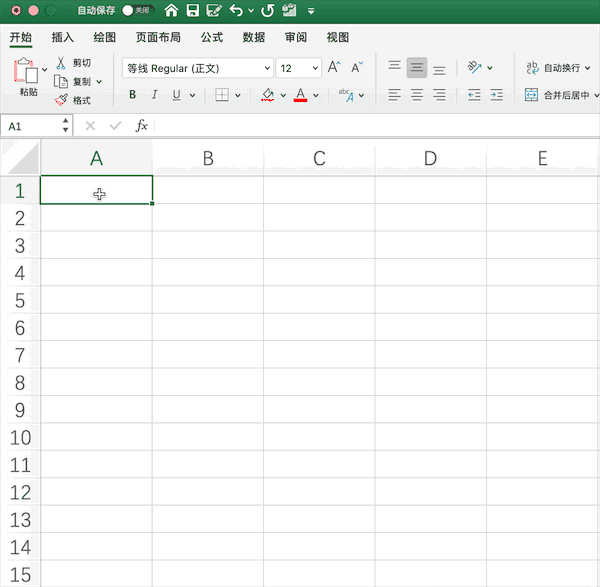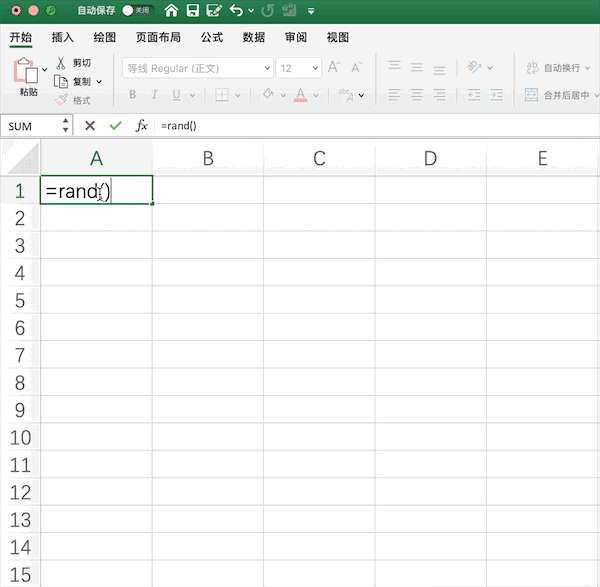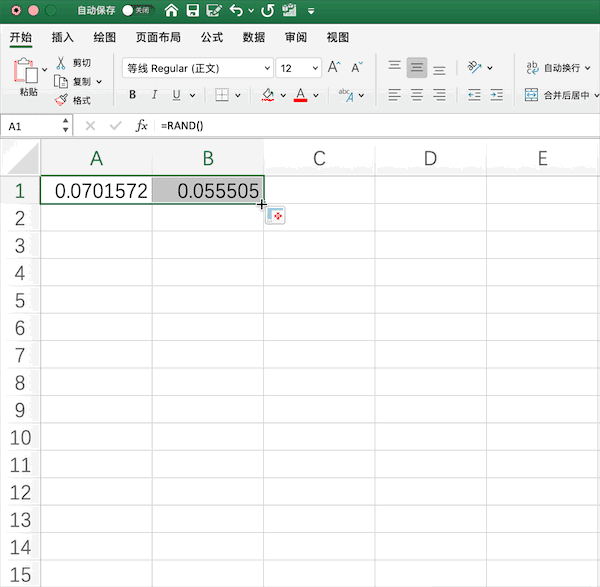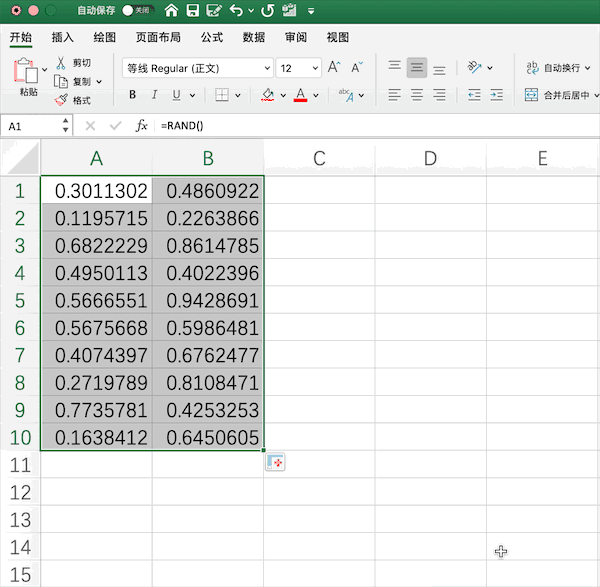
Pandas¶
在Pandas中可以结合NumPy生成由指定随机数(均匀分布、正态分布等)生成的矩阵,例如同样生成10*2的0—1均匀分布随机数矩阵为,使用一行代码即可:pd.DataFrame(np.random.rand(10,2))
import numpy as np
pd.DataFrame(np.random.rand(10,2))
| 0 | 1 | |
|---|---|---|
| 0 | 0.731228 | 0.311061 |
| 1 | 0.400904 | 0.592247 |
| 2 | 0.531014 | 0.797781 |
| 3 | 0.267304 | 0.361800 |
| 4 | 0.454464 | 0.051818 |
| 5 | 0.608874 | 0.832793 |
| 6 | 0.617377 | 0.556913 |
| 7 | 0.345005 | 0.146446 |
| 8 | 0.095227 | 0.676246 |
| 9 | 0.913447 | 0.796782 |
3 - 数据存储¶
Pandas¶
在Pandas中可以使用pd.to_excel("filename.xlsx")来将当前工作表格保存至当前目录下,当然也可以使用to_csv保存为csv等其他格式,也可以使用绝对路径来指定保存位置
# data.to_excel("测试数据.xlsx")
4 - 数据筛选¶
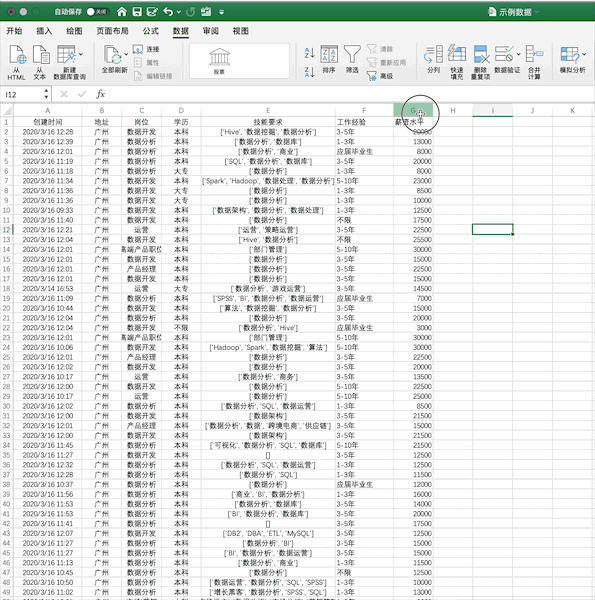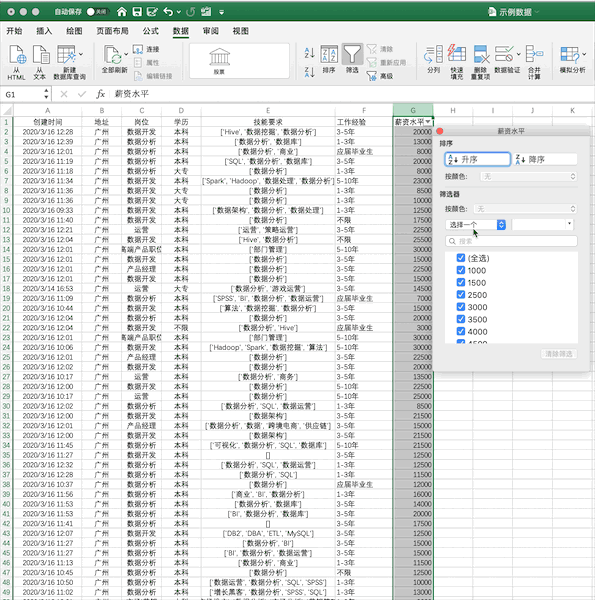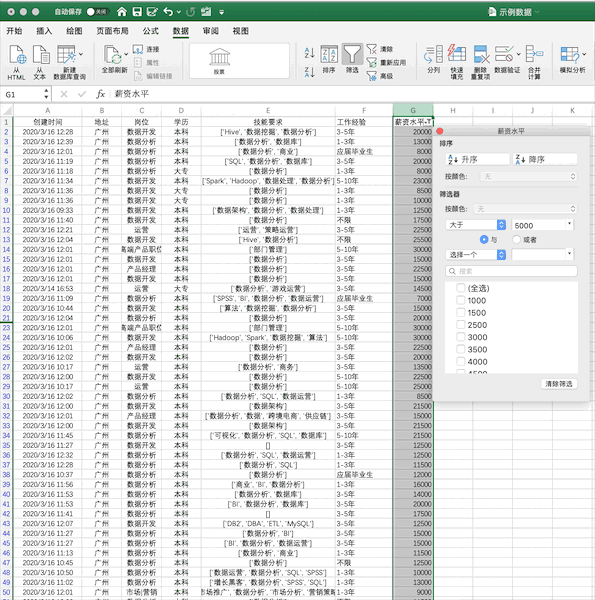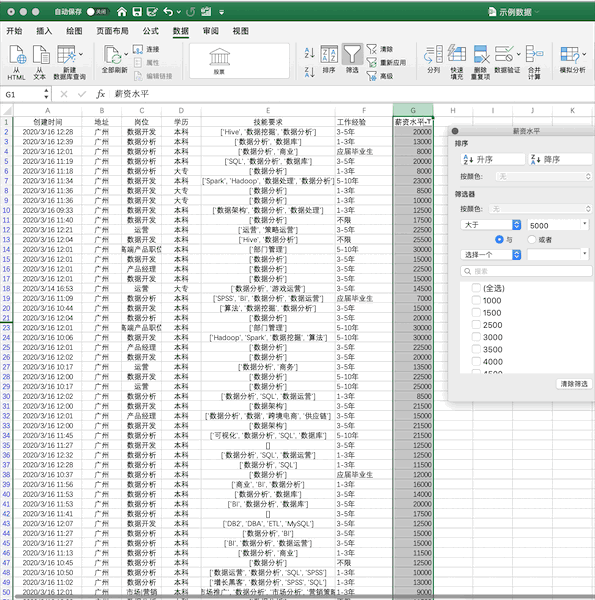
Pandas¶
在Pandas中,可直接对数据框进行条件筛选,例如同样进行单个条件(薪资大于5000)的筛选可以使用df[df['薪资水平']>5000],如果使用多个条件的筛选只需要使用&(并)与|(或)操作符实现
df = pd.read_excel("示例数据.xlsx")
df[df['薪资水平']>5000]
| 创建时间 | 地址 | 岗位 | 学历 | 技能要求 | 工作经验 | 薪资水平 | |
|---|---|---|---|---|---|---|---|
| 0 | 2020-03-16 12:28:11 | 广州 | 数据开发 | 本科 | ['Hive', '数据挖掘', '数据分析'] | 3-5年 | 20000.0 |
| 1 | 2020-03-16 12:39:03 | 广州 | 数据分析 | 本科 | ['数据分析', '数据库'] | 1-3年 | 13000.0 |
| 2 | 2020-03-16 12:01:37 | 广州 | 数据分析 | 本科 | ['数据分析', '商业'] | 应届毕业生 | 8000.0 |
| 3 | 2020-03-16 11:19:51 | 广州 | 数据分析 | 本科 | ['SQL', '数据分析', '数据库'] | 3-5年 | 20000.0 |
| 4 | 2020-03-16 11:18:49 | 广州 | 数据分析 | 大专 | ['数据分析'] | 1-3年 | 8000.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 817 | 2020-03-16 11:20:42 | 深圳 | 数据分析 | 本科 | [] | 1-3年 | 11500.0 |
| 819 | 2020-03-16 11:20:44 | 深圳 | 数据分析 | 本科 | [] | 1-3年 | 15000.0 |
| 820 | 2020-03-16 11:20:44 | 深圳 | 数据分析 | 本科 | [] | 1年以下 | 11500.0 |
| 822 | 2020-03-16 10:33:46 | 深圳 | 数据分析 | 本科 | ['BI', '数据分析', 'SQL', '数据库'] | 3-5年 | 16500.0 |
| 823 | 2020-03-16 11:20:43 | 深圳 | 数据开发 | 本科 | [] | 不限 | 11500.0 |
776 rows × 7 columns
5 - 数据插入¶
Excel¶
在Excel中我们可以将光标放在指定位置并右键增加一行/列,当然也可以在添加时对数据进行一些计算,比如我们就可以使用IF函数(=IF(G2>10000,"高","低")),将薪资大于10000的设为高,低于10000的设为低,添加一列在最后

Pandas¶
在 pandas 中,如果不借助自定义函数的话,我们可以使用cut方法来实现同样操作
bins = [0,10000,max(df['薪资水平'])]
group_names = ['低','高']
df['new_col'] = pd.cut(df['薪资水平'], bins, labels=group_names)
7 - 数据排序¶

Pandas¶
在pandas中可以使用sort_values进行排序,使用ascending来控制升降序,例如将示例数据按照薪资从高到低进行排序可以使用df.sort_values("薪资水平",ascending=False,inplace=True)
df1 = df
df1.sort_values("薪资水平",ascending=False)
df1
| 创建时间 | 地址 | 岗位 | 学历 | 技能要求 | 工作经验 | 薪资水平 | new_col | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-03-16 12:28:11 | 广州 | 数据开发 | 本科 | ['Hive', '数据挖掘', '数据分析'] | 3-5年 | 20000.0 | 高 |
| 1 | 2020-03-16 12:39:03 | 广州 | 数据分析 | 本科 | ['数据分析', '数据库'] | 1-3年 | 13000.0 | 高 |
| 2 | 2020-03-16 12:01:37 | 广州 | 数据分析 | 本科 | ['数据分析', '商业'] | 应届毕业生 | 8000.0 | 低 |
| 3 | 2020-03-16 11:19:51 | 广州 | 数据分析 | 本科 | ['SQL', '数据分析', '数据库'] | 3-5年 | 20000.0 | 高 |
| 4 | 2020-03-16 11:18:49 | 广州 | 数据分析 | 大专 | ['数据分析'] | 1-3年 | 8000.0 | 低 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 820 | 2020-03-16 11:20:44 | 深圳 | 数据分析 | 本科 | [] | 1年以下 | 11500.0 | 高 |
| 821 | 2020-03-16 11:20:42 | 深圳 | 数据开发 | 本科 | [] | 应届毕业生 | 4500.0 | 低 |
| 822 | 2020-03-16 10:33:46 | 深圳 | 数据分析 | 本科 | ['BI', '数据分析', 'SQL', '数据库'] | 3-5年 | 16500.0 | 高 |
| 823 | 2020-03-16 11:20:43 | 深圳 | 数据开发 | 本科 | [] | 不限 | 11500.0 | 高 |
| 824 | 2020-03-16 10:37:24 | 深圳 | 数据分析 | 本科 | [] | 不限 | 3000.0 | 低 |
825 rows × 8 columns
8 - 缺失值处理¶

Pandas¶
在pandas中可以使用 data.isnull().sum() 来检查缺失值,之后可以使用多种方法来填充或者删除缺失值,比如我们可以使用df = df.fillna(axis=0,method='ffill') 来横向/纵向用缺失值前面的值替换缺失值
df.isnull().sum()
创建时间 0
地址 0
岗位 0
学历 0
技能要求 0
工作经验 0
薪资水平 2
new_col 2
dtype: int64
9 - 数据去重¶

Pandas¶
在pandas中可以使用drop_duplicates来对数据进行去重,并且可以指定列以及保留顺序,例如对示例数据按照创建时间列进行去重df.drop_duplicates(['创建时间'],inplace=True),可以发现和Excel处理的结果一致,保留了 629 个唯一值。
df.drop_duplicates(['创建时间'],inplace=True)
df
| 创建时间 | 地址 | 岗位 | 学历 | 技能要求 | 工作经验 | 薪资水平 | new_col | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-03-16 12:28:11 | 广州 | 数据开发 | 本科 | ['Hive', '数据挖掘', '数据分析'] | 3-5年 | 20000.0 | 高 |
| 1 | 2020-03-16 12:39:03 | 广州 | 数据分析 | 本科 | ['数据分析', '数据库'] | 1-3年 | 13000.0 | 高 |
| 2 | 2020-03-16 12:01:37 | 广州 | 数据分析 | 本科 | ['数据分析', '商业'] | 应届毕业生 | 8000.0 | 低 |
| 3 | 2020-03-16 11:19:51 | 广州 | 数据分析 | 本科 | ['SQL', '数据分析', '数据库'] | 3-5年 | 20000.0 | 高 |
| 4 | 2020-03-16 11:18:49 | 广州 | 数据分析 | 大专 | ['数据分析'] | 1-3年 | 8000.0 | 低 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 811 | 2020-03-16 11:03:17 | 深圳 | 数据开发 | 本科 | ['Hive', '数据分析', '数据仓库', '信息安全'] | 3-5年 | 37000.0 | 高 |
| 812 | 2020-03-16 11:03:03 | 深圳 | 数据开发 | 本科 | ['数据挖掘', '数据分析'] | 不限 | 30000.0 | 高 |
| 815 | 2020-03-16 11:00:56 | 深圳 | 数据分析 | 本科 | ['BI', '数据分析', 'SQL', '数据库'] | 5-10年 | 45000.0 | 高 |
| 817 | 2020-03-16 11:20:42 | 深圳 | 数据分析 | 本科 | [] | 1-3年 | 11500.0 | 高 |
| 824 | 2020-03-16 10:37:24 | 深圳 | 数据分析 | 本科 | [] | 不限 | 3000.0 | 低 |
629 rows × 8 columns
10 - 格式修改¶

Pandas¶
在Pandas中没有一个固定修改格式的方法,不同的数据格式有着不同的修改方法,比如类似Excel中将创建时间修改为年-月-日可以使用df['创建时间'] = df['创建时间'].dt.strftime('%Y-%m-%d')
df1 = df
df1['创建时间'] = df1['创建时间'].dt.strftime('%Y-%m-%d')
11 - 数据交换¶
Pandas¶
在 pandas 中交换两列也有很多方法,以交换示例数据中地址与岗位两列为例,可以通过修改列号来实现
cols = df.columns[[0,2,1,3,4,5,6]]
df1 = df[cols]
12 - 数据合并¶
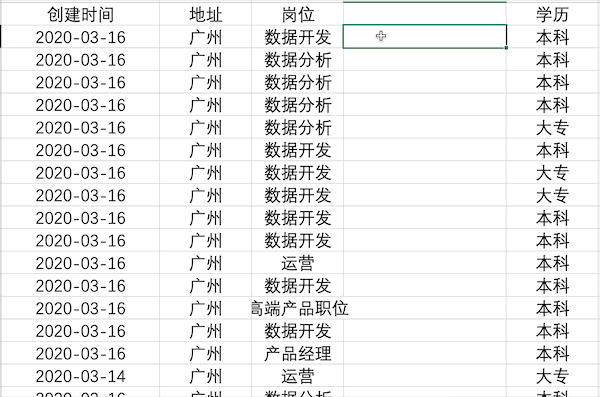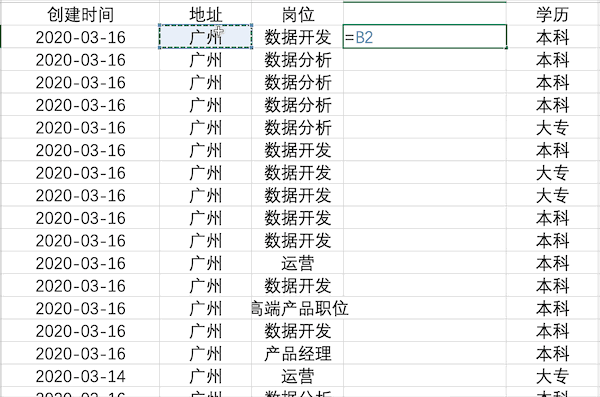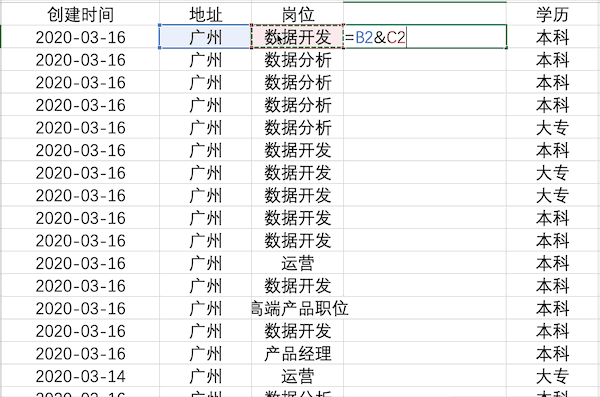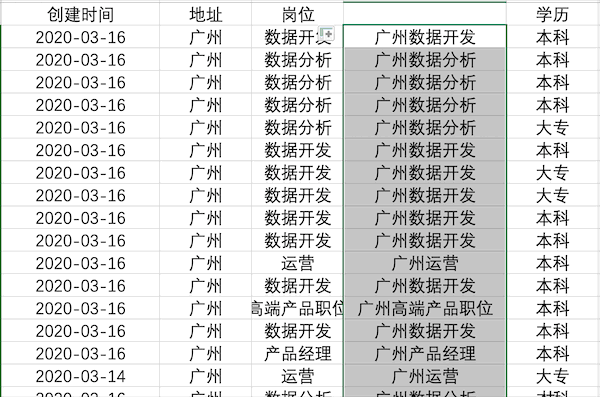
Pandas¶
在Pandas中合并多列比较简单,类似于之前的数据插入操作,例如合并示例数据中的地址+岗位列使用df['合并列'] = df['地址'] + df['岗位']
df['合并列'] = df['地址'] + df['岗位']
13 - 数据拆分¶

Pandas¶
在Pandas中可以使用.split来完成分列,但是在分列完毕后需要使用 merge 来将分列完的数据添加至原DataFrame,对于分列完的数据含有[]字符,我们可以使用正则或者字符串lstrip方法进行处理,但因不是pandas特性,此处不再展开。
df['技能要求'].str.split(',',expand=True)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | ['Hive' | '数据挖掘' | '数据分析'] | None |
| 1 | ['数据分析' | '数据库'] | None | None |
| 2 | ['数据分析' | '商业'] | None | None |
| 3 | ['SQL' | '数据分析' | '数据库'] | None |
| 4 | ['数据分析'] | None | None | None |
| ... | ... | ... | ... | ... |
| 811 | ['Hive' | '数据分析' | '数据仓库' | '信息安全'] |
| 812 | ['数据挖掘' | '数据分析'] | None | None |
| 815 | ['BI' | '数据分析' | 'SQL' | '数据库'] |
| 817 | [] | None | None | None |
| 824 | [] | None | None | None |
629 rows × 4 columns
14 - 数据分组¶

Pandas¶
在Pandas中对数据进行分组计算可以使用groupby轻松搞定,比如使用df.groupby("学历").mean()一行代码即可对示例数据的学历进行分组并求不同学历的平均薪资,结果与Excel一致
15 - 数据计算¶
Pandas¶
在Pandas中可以直接使用类似数据筛选的方法来统计薪资大于10000的岗位数量len(df[df["薪资水平"]>10000])
len(df[df["薪资水平"]>10000])
518
16 - 数据统计¶
Pandas¶
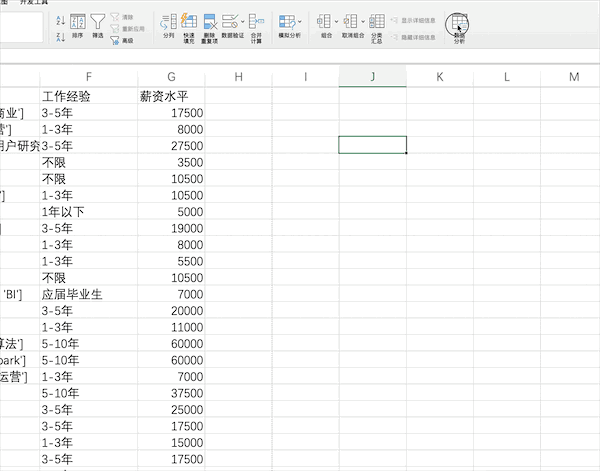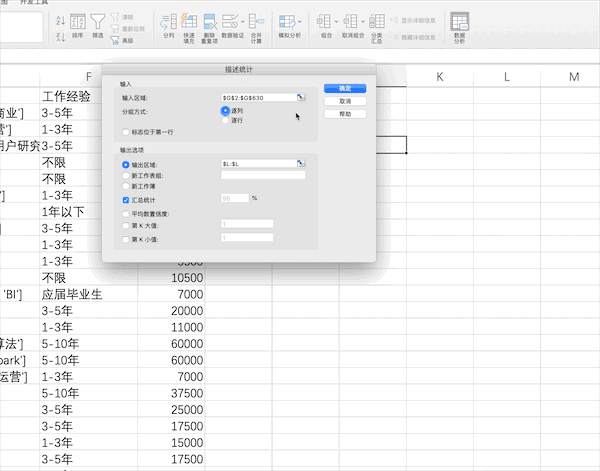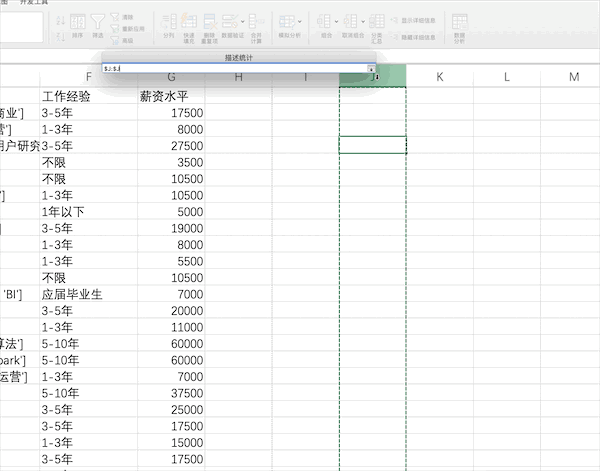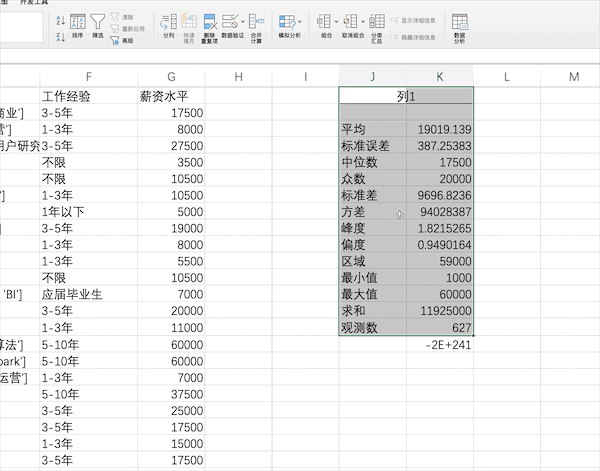
在pandas中也有现成的函数describe快速完成对数据的描述性统计,比如使用df["薪资水平"].describe()即可得到薪资列的描述性统计结果
df["薪资水平"].describe()
count 627.000000
mean 19019.138756
std 9696.823558
min 1000.000000
25% 12500.000000
50% 17500.000000
75% 25000.000000
max 60000.000000
Name: 薪资水平, dtype: float64
17 - 数据可视化¶
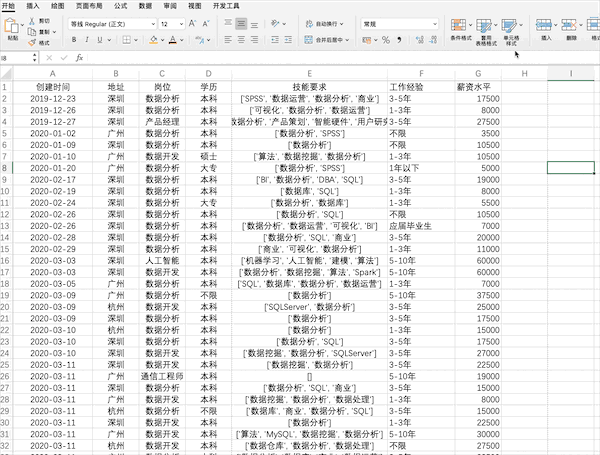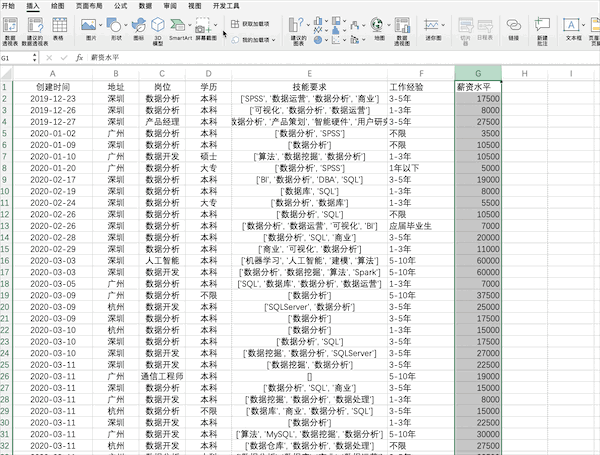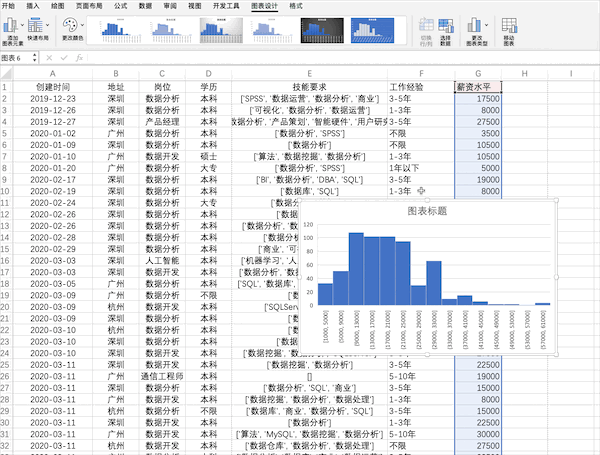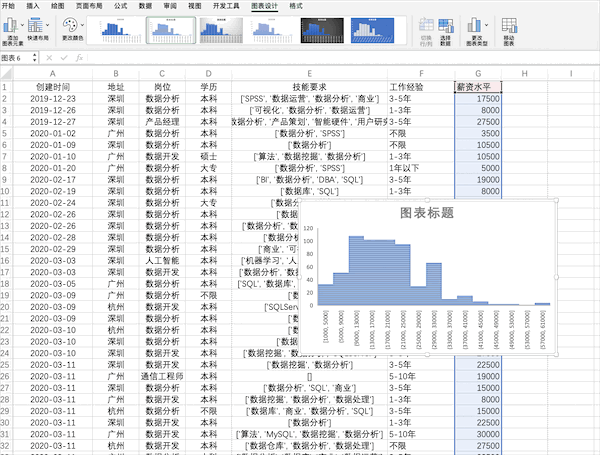
Pandas¶
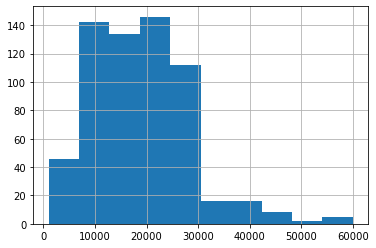
在Pandas中也支持直接对数据绘制不同可视化图表,例如直方图,可以使用plot或者直接使用hist来制作df[“薪资水平”].hist()
df["薪资水平"].hist()
<AxesSubplot:>
18 - 数据抽样¶
Pandas¶
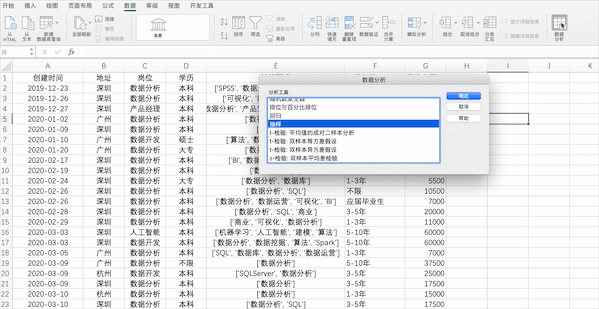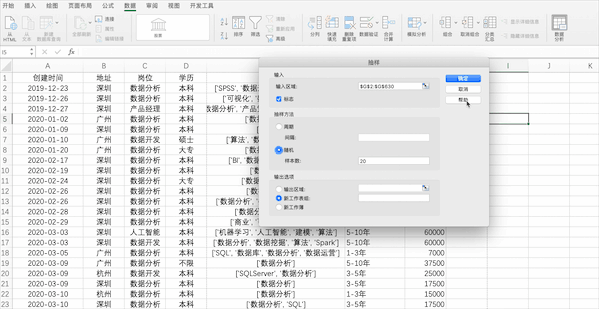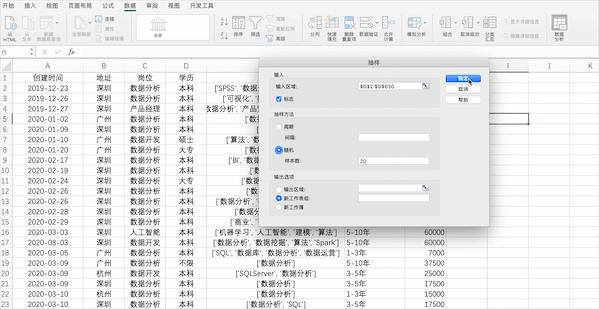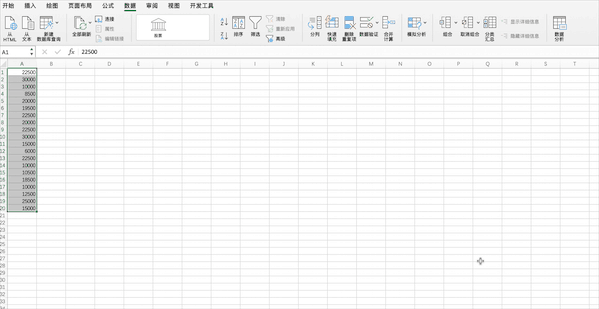
在pandas中有抽样函数sample可以直接抽样,并且支持任意格式的数据抽样,可以按照数量/比例抽样,比如随机抽20个示例数据中的样本
df.sample(20)
| 创建时间 | 地址 | 岗位 | 学历 | 技能要求 | 工作经验 | 薪资水平 | new_col | 合并列 | |
|---|---|---|---|---|---|---|---|---|---|
| 502 | 2020-03-16 | 上海 | 数据分析 | 本科 | ['数据库', 'SQL', '数据分析'] | 1-3年 | 14000.0 | 高 | 上海数据分析 |
| 346 | 2020-03-16 | 北京 | 数据分析 | 本科 | ['数据分析', 'BI', 'SQL', '数据库'] | 3-5年 | 27500.0 | 高 | 北京数据分析 |
| 232 | 2020-03-15 | 杭州 | 数据分析 | 本科 | ['BI', 'SQL'] | 3-5年 | 30000.0 | 高 | 杭州数据分析 |
| 46 | 2020-03-16 | 广州 | 数据分析 | 本科 | ['数据运营', '数据分析', 'SQL', 'SPSS'] | 1-3年 | 10000.0 | 低 | 广州数据分析 |
| 253 | 2020-03-15 | 杭州 | 数据分析 | 大专 | ['BI', '数据分析', '数据运营', 'SPSS'] | 3-5年 | 30000.0 | 高 | 杭州数据分析 |
| 314 | 2020-03-16 | 北京 | 数据开发 | 本科 | ['数据挖掘'] | 5-10年 | 30000.0 | 高 | 北京数据开发 |
| 772 | 2020-03-13 | 深圳 | 数据分析 | 本科 | ['数据分析', 'SQL'] | 5-10年 | 15000.0 | 高 | 深圳数据分析 |
| 420 | 2020-03-16 | 北京 | 数据分析 | 本科 | ['产品'] | 3-5年 | 16000.0 | 高 | 北京数据分析 |
| 572 | 2020-03-16 | 深圳 | 数据开发 | 本科 | ['Hadoop', 'Spark'] | 1-3年 | 25000.0 | 高 | 深圳数据开发 |
| 156 | 2020-01-10 | 广州 | 数据开发 | 硕士 | ['算法', '数据挖掘', '数据分析'] | 1-3年 | 10500.0 | 高 | 广州数据开发 |
| 741 | 2020-03-16 | 深圳 | 保险 | 本科 | ['保险'] | 1年以下 | 15000.0 | 高 | 深圳保险 |
| 174 | 2020-03-16 | 杭州 | 数据开发 | 本科 | ['Hive', '数据挖掘', '数据分析', 'SQLServer'] | 1-3年 | 16000.0 | 高 | 杭州数据开发 |
| 27 | 2020-03-16 | 广州 | 运营 | 本科 | ['数据分析'] | 5-10年 | 25000.0 | 高 | 广州运营 |
| 625 | 2020-03-16 | 深圳 | 数据分析 | 本科 | ['数据运营', '数据分析'] | 3-5年 | 18000.0 | 高 | 深圳数据分析 |
| 479 | 2020-03-16 | 上海 | 运营 | 本科 | ['数据分析', '游戏运营'] | 1-3年 | 12000.0 | 高 | 上海运营 |
| 328 | 2020-03-15 | 北京 | 数据分析 | 本科 | ['数据分析'] | 1-3年 | 22500.0 | 高 | 北京数据分析 |
| 786 | 2020-03-13 | 深圳 | 运营 | 本科 | ['数据分析', '游戏运营'] | 应届毕业生 | 8500.0 | 低 | 深圳运营 |
| 759 | 2020-03-03 | 深圳 | 人工智能 | 本科 | ['机器学习', '人工智能', '建模', '算法'] | 5-10年 | 60000.0 | 高 | 深圳人工智能 |
| 394 | 2020-03-16 | 北京 | 数据分析 | 本科 | ['BI'] | 3-5年 | 30000.0 | 高 | 北京数据分析 |
| 418 | 2020-03-16 | 北京 | 数据分析 | 本科 | [] | 3-5年 | 30000.0 | 高 | 北京数据分析 |
19 - 数据透视表¶
Excel¶
数据透视表是一个非常强大的工具,在Excel中有现成的工具,只需要选中数据—>点击插入—>数据透视表即可生成,并且支持字段的拖取实现不同的透视表,非常方便,比如制作地址、学历、薪资的透视表
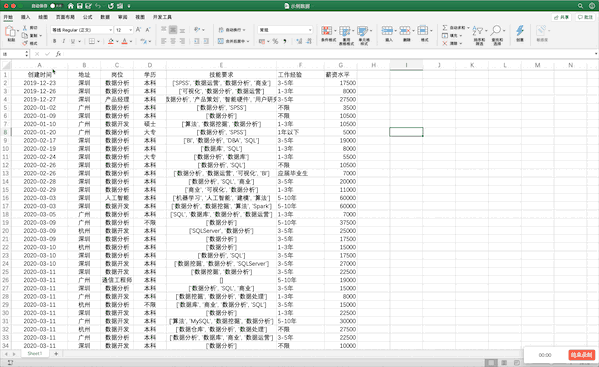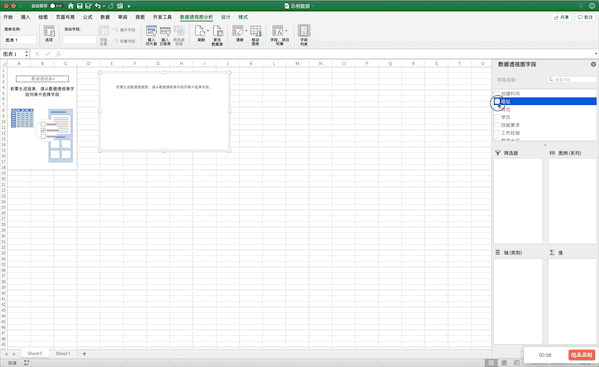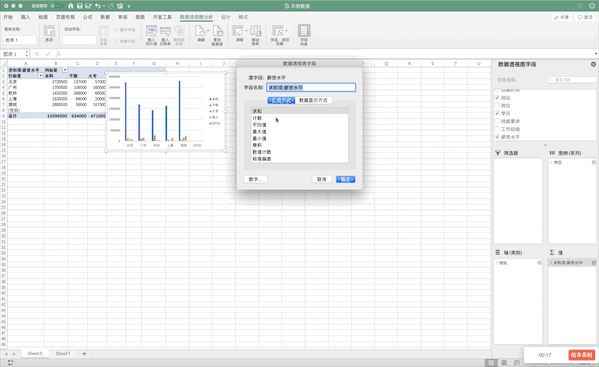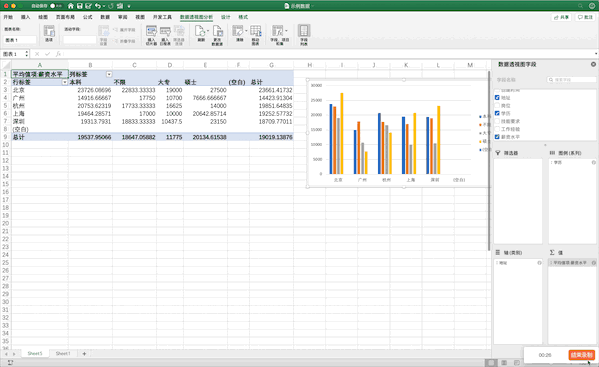
Pandas¶
在Pandas中制作数据透视表可以使用pivot_table函数,例如制作地址、学历、薪资的透视表pd.pivot_table(df,index=["地址","学历"],values=["薪资水平"]),虽然结果一样,但是并没有Excel一样方便调整与多样
pd.pivot_table(df,index=["地址","学历"],values=["薪资水平"])
| 薪资水平 | ||
|---|---|---|
| 地址 | 学历 | |
| 上海 | 不限 | 17000.000000 |
| 大专 | 10000.000000 | |
| 本科 | 19464.285714 | |
| 硕士 | 20642.857143 | |
| 北京 | 不限 | 22833.333333 |
| 大专 | 19000.000000 | |
| 本科 | 23726.086957 | |
| 硕士 | 27500.000000 | |
| 广州 | 不限 | 17750.000000 |
| 大专 | 10700.000000 | |
| 本科 | 14916.666667 | |
| 硕士 | 7666.666667 | |
| 杭州 | 不限 | 17733.333333 |
| 大专 | 16625.000000 | |
| 本科 | 20753.623188 | |
| 硕士 | 14000.000000 | |
| 深圳 | 不限 | 18833.333333 |
| 大专 | 10437.500000 | |
| 本科 | 19313.793103 | |
| 硕士 | 23150.000000 |
20 - vlookup¶

Pandas¶
在Pandas中没有现成的vlookup函数,所以实现匹配查找需要一些步骤,首先我们读取该表格
df1 = pd.read_excel("vlookup.xlsx")
df1
| 序号 | 科目 | 成绩 | 排名 | Unnamed: 4 | 序号.1 | 科目.1 | 成绩.1 | 排名.1 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 语文 | 80 | 8 | NaN | C | NaN | NaN | NaN |
| 1 | B | 数学 | 70 | 2 | NaN | NaN | NaN | NaN | NaN |
| 2 | C | 英语 | 60 | 4 | NaN | NaN | NaN | NaN | NaN |
| 3 | D | 政治 | 50 | 5 | NaN | NaN | NaN | NaN | NaN |
| 4 | E | 地理 | 90 | 6 | NaN | NaN | NaN | NaN | NaN |
| 5 | F | 化学 | 100 | 1 | NaN | NaN | NaN | NaN | NaN |
| 6 | G | 生物 | 77 | 3 | NaN | NaN | NaN | NaN | NaN |
接着将该dataframe切分为两个
df2 = df1[["序号","科目","成绩","排名"]]
df2
| 序号 | 科目 | 成绩 | 排名 | |
|---|---|---|---|---|
| 0 | A | 语文 | 80 | 8 |
| 1 | B | 数学 | 70 | 2 |
| 2 | C | 英语 | 60 | 4 |
| 3 | D | 政治 | 50 | 5 |
| 4 | E | 地理 | 90 | 6 |
| 5 | F | 化学 | 100 | 1 |
| 6 | G | 生物 | 77 | 3 |
df3 = df1[["序号.1","科目.1","成绩.1","排名.1"]]
df3.columns = ["序号","科目","成绩","排名"]
df3 = df3.loc[0:0]
df3
| 序号 | 科目 | 成绩 | 排名 | |
|---|---|---|---|---|
| 0 | C | NaN | NaN | NaN |
最后修改索引并使用update进行两表的匹配
df2 = df2.set_index("序号")
df3 = df3.set_index("序号")
df3.update(df2)
df3
| 科目 | 成绩 | 排名 | |
|---|---|---|---|
| 序号 | |||
| C | 英语 | 60.0 | 4.0 |