
Zaoqi's Blog -> Python数据分析教程 -> 图解Pandas ->
concat - 数据拼接
concat - 数据拼接¶
在线刷题
检查 or 强化 Pandas 数据分析操作?👉在线体验「Pandas进阶修炼300题」
Note
本页面代码可以在线编辑、执行!
concat 我翻译成数据拼接,需要和 merge 进行区分,在进行 concat 时一个重要的参数就是 axis ,下图是一个简单的例子
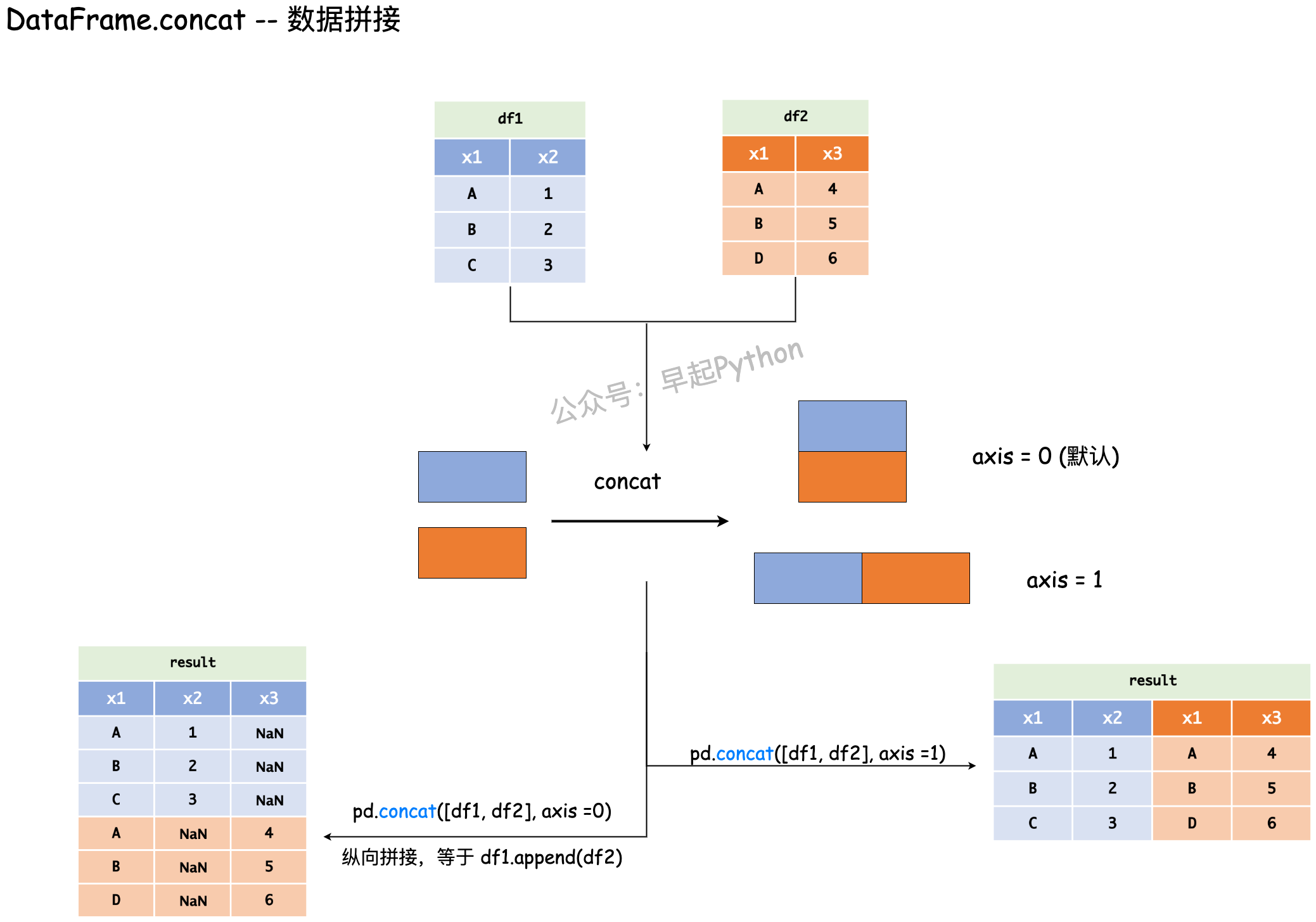
下面是官方文档中的案例,你可以修改相关代码来验证自己的想法!
本页数据说明¶
在学习本页面操作时,应先了解大致数据结构如下

import pandas as pd
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])
df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
默认拼接¶
垂直拼接 df1、df2、df3,效果如下图所示
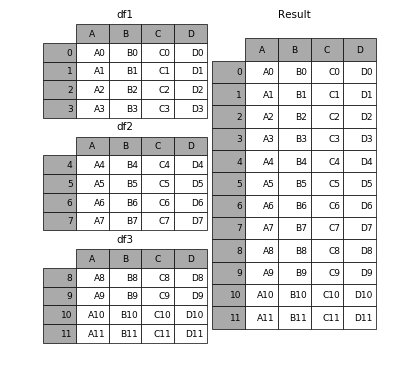
pd.concat([df1, df2, df3])
| A | B | C | D | |
|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | D2 |
| 3 | A3 | B3 | C3 | D3 |
| 4 | A4 | B4 | C4 | D4 |
| 5 | A5 | B5 | C5 | D5 |
| 6 | A6 | B6 | C6 | D6 |
| 7 | A7 | B7 | C7 | D7 |
| 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 |
| 10 | A10 | B10 | C10 | D10 |
| 11 | A11 | B11 | C11 | D11 |
重置索引¶
垂直拼接 df1 和 df4,并按顺序重新生成索引,
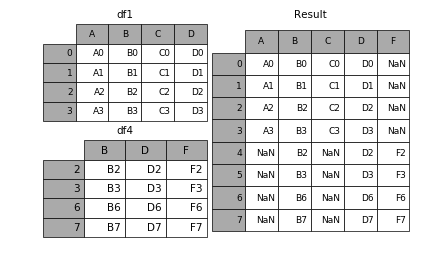
pd.concat([df1, df4], ignore_index=True)
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN |
| 2 | A2 | B2 | C2 | D2 | NaN |
| 3 | A3 | B3 | C3 | D3 | NaN |
| 4 | NaN | B2 | NaN | D2 | F2 |
| 5 | NaN | B3 | NaN | D3 | F3 |
| 6 | NaN | B6 | NaN | D6 | F6 |
| 7 | NaN | B7 | NaN | D7 | F7 |
横向拼接¶
横向拼接 df1、df4,效果如下图所示
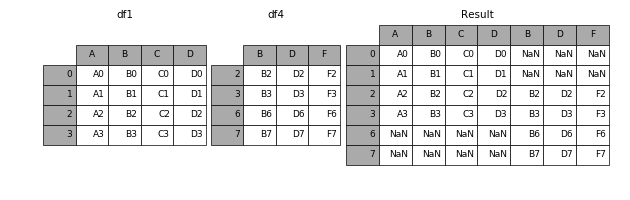
pd.concat([df1,df4],axis=1)
| A | B | C | D | B | D | F | |
|---|---|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN | NaN | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN | NaN | NaN |
| 2 | A2 | B2 | C2 | D2 | B2 | D2 | F2 |
| 3 | A3 | B3 | C3 | D3 | B3 | D3 | F3 |
| 6 | NaN | NaN | NaN | NaN | B6 | D6 | F6 |
| 7 | NaN | NaN | NaN | NaN | B7 | D7 | F7 |
横向拼接(取交集)¶
在上一题的基础上,只取结果的交集
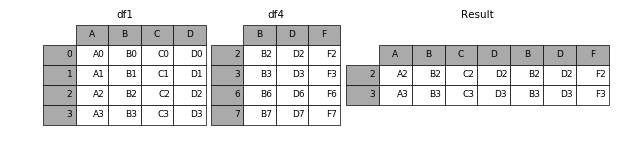
pd.concat([df1,df4],axis=1,join='inner')
| A | B | C | D | B | D | F | |
|---|---|---|---|---|---|---|---|
| 2 | A2 | B2 | C2 | D2 | B2 | D2 | F2 |
| 3 | A3 | B3 | C3 | D3 | B3 | D3 | F3 |
横向拼接(取指定)¶
在 14 题基础上,只取包含 df1 索引的部分
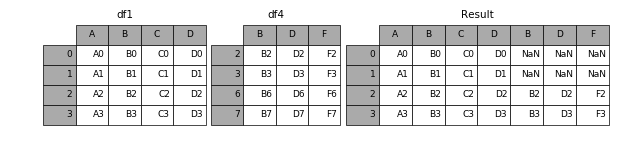
pd.concat([df1, df4], axis=1).reindex(df1.index)
| A | B | C | D | B | D | F | |
|---|---|---|---|---|---|---|---|
| 0 | A0 | B0 | C0 | D0 | NaN | NaN | NaN |
| 1 | A1 | B1 | C1 | D1 | NaN | NaN | NaN |
| 2 | A2 | B2 | C2 | D2 | B2 | D2 | F2 |
| 3 | A3 | B3 | C3 | D3 | B3 | D3 | F3 |
新增索引¶
拼接 df1、df2、df3,同时新增一个索引(x、y、z)来区分不同的表数据来源
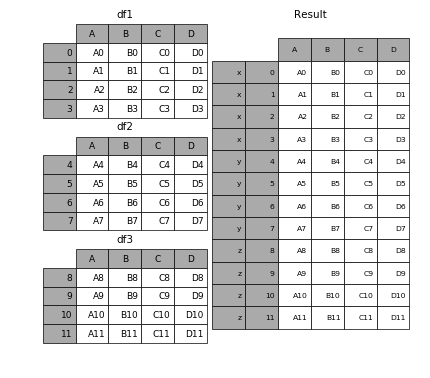
pd.concat([df1, df2, df3], keys=['x', 'y', 'z'])
| A | B | C | D | ||
|---|---|---|---|---|---|
| x | 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 | |
| 2 | A2 | B2 | C2 | D2 | |
| 3 | A3 | B3 | C3 | D3 | |
| y | 4 | A4 | B4 | C4 | D4 |
| 5 | A5 | B5 | C5 | D5 | |
| 6 | A6 | B6 | C6 | D6 | |
| 7 | A7 | B7 | C7 | D7 | |
| z | 8 | A8 | B8 | C8 | D8 |
| 9 | A9 | B9 | C9 | D9 | |
| 10 | A10 | B10 | C10 | D10 | |
| 11 | A11 | B11 | C11 | D11 |
On this page