{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# join - 横向连接\n",
"\n",
"`DataFrame.join`是一种将两个可能具有不同索引的 `DataFrame` 的列组合成单个 `DataFrame` 的便捷方法。\n",
"\n",
"```{admonition} 在线刷题\n",
":class: seealso\n",
"\n",
"检查 or 强化 `Pandas` 数据分析操作?👉在线体验「Pandas进阶修炼300题」\n",
"```\n",
"\n",
"```{note} \n",
"本页面代码可以[在线编辑、执行](../指引/在线执行.md)!\n",
"```\n",
"\n",
"\n",
"`join` 本质上和 [merge](merge.ipynb) 类似,或者说是 `merge` 的特殊情况,所以也是一种 `SQL` 风格的合并方法。\n",
"\n",
"但和 `merge` 不一样的地方在于,`join` **只能按照行索引去合并数据,因此我翻译成 「横向连接」**。\n",
"\n",
"有关 `join` 的基本用法可以通过下图大致了解,至于 `how` 参数中的 `inner、outer` 可以参考 [merge](merge.ipynb) 中的图解。\n",
"\n",
"\n",
"```{figure} https://pic.liuzaoqi.com/picgo/202112242051282.png\n",
":width: 100%\n",
":align: center\n",
"```\n",
"\n",
"需要注意的是 `df2` 与 `df3` 的连接,如果有重复的列名,需要指定合并后左右的列名后缀,否则会报错。\n",
"\n",
"下面是官方文档中的案例,你可以修改相关代码来验证自己的想法!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
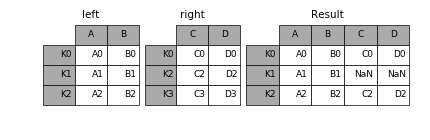
"## 默认方法\n",
"\n",
"组合 left 和 right,并按照 left 的索引进行对齐"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"tags": [
"hide-input",
"thebe-init"
]
},
"outputs": [],
"source": [
"import pandas as pd\n",
"left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],\n",
" 'B': ['B0', 'B1', 'B2']},\n",
" index=['K0', 'K1', 'K2'])\n",
"\n",
"\n",
"right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],\n",
" 'D': ['D0', 'D2', 'D3']},\n",
" index=['K0', 'K2', 'K3'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" A | \n",
" B | \n",
" C | \n",
" D | \n",
"
\n",
" \n",
" \n",
" \n",
" | K0 | \n",
" A0 | \n",
" B0 | \n",
" C0 | \n",
" D0 | \n",
"
\n",
" \n",
" | K1 | \n",
" A1 | \n",
" B1 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | K2 | \n",
" A2 | \n",
" B2 | \n",
" C2 | \n",
" D2 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" A | \n",
" B | \n",
" C | \n",
" D | \n",
"
\n",
" \n",
" \n",
" \n",
" | K0 | \n",
" A0 | \n",
" B0 | \n",
" C0 | \n",
" D0 | \n",
"
\n",
" \n",
" | K1 | \n",
" A1 | \n",
" B1 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | K2 | \n",
" A2 | \n",
" B2 | \n",
" C2 | \n",
" D2 | \n",
"
\n",
" \n",
" | K3 | \n",
" NaN | \n",
" NaN | \n",
" C3 | \n",
" D3 | \n",
"
\n",
" \n",
"
\n",
"